| 목차 >> Spring Batch +- Spring Batch 란 ----+- xmlns:batch 네임스페이스 ----+- ItemReader & ItemWriter +- Glue Batch +- Glue ItemReader & ItemWriter ----+- GlueCursorItemReader & GlueJdbcBatchItemWriter ----+- GlueDefaultItemReader & GlueDefaultItemWriter ----+- GlueCompositeCursorReader & GlueCompositeFileReader +- Glue JobLauncher ----+- GlueQuartzJobLauncher ----+- GlueJobLaunch |
Glue Framework에서 제공하는 Glue Batch 모듈은 Spring Batch를 기반으로 합니다. Glue Batch 모듈의 원활한 적용을 위해서는 Spring Batch 에 대한 기본적인 이해를 전제로 합니다.
이번 장에서는 Spring Batch 를 조금 다루고 있으나, 보다 자세한 것은 Spring Batch 사이트를 참고하시기 바랍니다.
Batch 어플리케이션은 사람의 도움없이 데이터를 자동으로 처리하기 때문에 견고하고 믿을 수 있어야 합니다.
그리고, Batch 어플리케이션이 처리하는 데이터의 양이 많을수록 처리시간도 길어지지만, 처리시간은 특정 시간 내로 제한되는 경우가 많기 때문에 Batch 어플리케이션의 수행 성능도 고려되어야 합니다.
Spring Batch 프로젝트는 Accenture 사의 현장 경험과 SpringSource 사의 기술력이 합쳐져서 탄생되었으며, Spring Batch의 목표는 Batch 어플리케이션의 요구사항을 효과적으로 해결하기 위한 Batch 기반 오픈소스 Framework을 제공하는 것입니다.
한가지 주의해야 할 점은 Spring Batch는 Scheduler가 아니라는 것입니다.
Spring Batch는 Batch Job 을 관리하지만 스케쥴링에 따라 Job을 구동하는 기능은 지원하지 않습니다.
Spring Batch는 Quartz 나 cron 과 같은 전용 Scheduler들에게 이런 역할을 하도록 하였습니다.
Scheduler는 일련의 연속된 Job을 실행시키기도 합니다. 예를 들어 Job A를 실행하고 Job A 가 성공적으로 끝나면 Job B를 실행하고 Job A가 실패하면 Job C를 실행시키기도 합니다.
Spring Batch는 이런 일련의 절차를 자체적으로 조정할 수 있습니다. Spring Batch의 Job 은 여러 개의 Step 으로 설정되고 각 Step의 실행순서는 스프링 배치 XML 을 사용해서 쉽게 설정할 수 있습니다.
Spring Batch 의 주요 기능들을 정리하면 아래와 같습니다(한국스프링사용자모임을 참고하였습니다).
Spring Batch 의 구성 요소를 정리하면 다음과 같습니다.
Job : Batch 처리를 의미하는 어플리케이션 컴포넌트
JobInstance : 논리적인 Job 실행.
JobInstance = Job + JobParameter
JobExecution : 단 한 번 시도되는 Job 실행을 의미.
시작시간, 종료시간, 상태(시작됨,완료,실패), 종료상태의 속성을 가짐
JobParameter : Batch Job을 시작하는데 사용하는 파라미터의 집합으로 Job이 실행되는 동안에 Job을 식별하거나 Job에서 참조하는 데이터로 사용됨.
| 그림 : 출처 - http://bcho.tistory.com/763 |
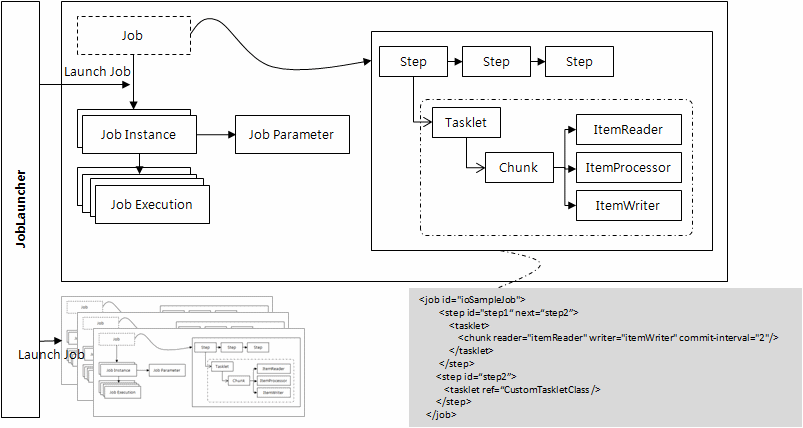
Step : Batch job을 구성하는 독립적인 하나의 단계.
Job은 하나이상의 step으로 구성됨.
실제 Batch 처리 과정을 정의하고, 제어하는데 필요한 모든 정보를 포함함.
Step Execution : 하나의 step을 실행하는 한번의 시도.
시작시간, 종료시간, 상태, 종료상태, commitCount, itemCount 의 속성을 가짐.
Tasklet : Tasklet 은 Step 내부의 트랜잭션 또는 반복될 수 있는 처리작업을 의미.
개발자들은 Tasklet 인터페이스를 직접 구현해서 사용하거나 스프링 배치가 제공하는 구현체를 사용할 수도 있음.
Chunk : 하나의 Transaction안에서 처리할 Item의 덩어리.
chunk size가 10이라면 하나의 transaction안에서 10개의 item에 대한 처리를 하고 commit을 하게 됨.
Job Launcher : Job 을 실행시키는 역할을 갖음.
JobRepository : 수행되는 Job에 대한 정보를 담고 있는 저장소.
어떠한 Job이 언제 수행되었고, 언제 끝났으며, 몇 번이 실행되었고 실행에 대한 결과가 어떤지 등의 Batch 수행과 관련된 모든 meta data가 저장됨.
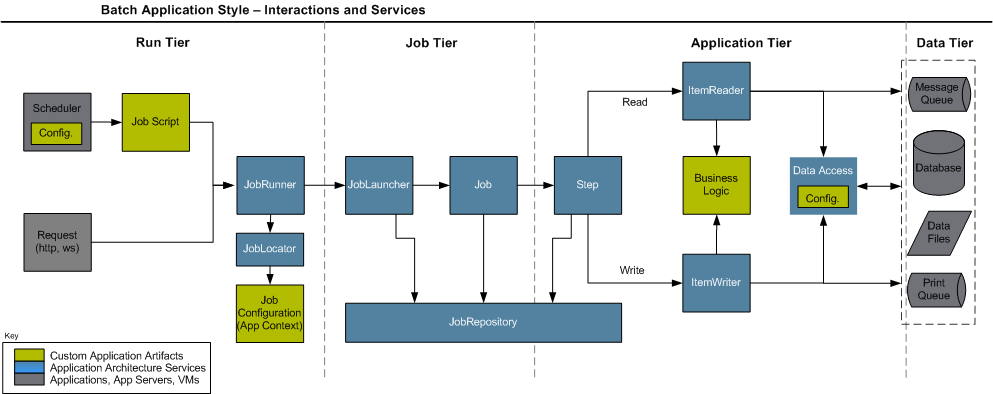
| 그림 : 출처 - http://docs.spring.io/spring-batch-old/1.1.x/spring-batch-docs/reference/html-single |
Spring 에서는 Spring Batch 설정 전용 XML 네임스페이스를 제공합니다.
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:batch="http://www.springframework.org/schema/batch"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.2.xsd
http://www.springframework.org/schema/batch
http://www.springframework.org/schema/batch/spring-batch-3.0.xsd">
<batch:job-repository />
<bean id="dataSource" . . ./>
<bean id="transactionManager" . . ./>
<batch:job id="job">
<batch:step id="step-1" next="step-2">
<batch:tasklet ref="tasklet" />
</batch:step>
<batch:step id="step-2">
<batch:tasklet>
<batch:chunk reader="reader" processor="bizProcessor" writer="writer" />
</batch:tasklet>
</batch:step>
</batch:job>
<bean id="tasklet" . . ./>
<bean id="bizProcessor" . . ./>
<bean id="reader" . . ./>
<bean id="writer" . . ./>
</beans>
batch 네임스페이스를 통해 사용할 수 있는 주요 태그는 다음과 같습니다.
job : 배치 job 을 설정한다.
스프링 배치로 배치 어플리케이션을 구현할 경우 최상위 엔티티는 <batch:job> 이며, 배치 처리를 정의할 때 가장 먼저 설정하는 엔티티입니다.
batch 네임스페이스의 job은 다음과 같은 속성을 갖습니다.
<batch:job id="samplejob" incrementer="customIncrementer">
. . .
</batch:job>
<bean id="customIncrementer" class=". . ."/>
step : 배치 step 을 설정한다.
<batch:step> 이란 job 의 각 단계를 나타냅니다. job 내부의 step 들은 job 이 수행해야 하는 일련의 처리 절차를 의미합니다.
batch 네임스페이스의 step은 다음과 같은 속성을 갖습니다.
<batch:job id="samplejob">
<batch:step id="sample1" next=" sample2">
. . .
</batch:step>
<batch:step id="sample2">
. . .
</batch:step>
</batch:job>
tasklet : step 내에서 사용되는 tasklet 을 설정한다.
<batch:tasklet> 은 각 step에서 수행되는 로직입니다. 개발자가 Custom Logic을 만들 수도 있으나, 또는 보통 Batch의 경우 데이타를 ETL (Extract, Transform, Loading) 하는 형태이기 때문에, Spring Batch에서 미리 정의해놓은 Reader, Processor, Writer Interface를 사용할 수 있습니다.
<batch:job id="samplejob">
<batch:step id="sample1" next=" sample2">
<batch:tasklet ref="customtasklet" />
</batch:step>
<batch:step id="sample2">
<batch:tasklet>
<batch:chunk reader="itemReader" writer="itemWriter" processor="ItemProcessor" commit-interval="500"/>
</batch:tasklet>
</batch:step>
</batch:job>
<bean id="customtasklet" . . . />
chunk : step 내에서 사용되는 chunk 를 설정한다.
<batch:job id="samplejob">
<batch:step id="sample2">
<batch:tasklet>
<batch:chunk reader="itemReader" writer="itemWriter" processor="itemProcessor" commit-interval="500"/>
</batch:tasklet>
</batch:step>
</batch:job>
<bean id="itemReader" . . . />
<bean id="itemWriter" . . . />
<bean id="itemProcessor" . . . />
job-repository : 메타데이터를 위한 job repository 를 설정한다.
<batch:job-repository id="jobRepository" data-source="dataSource" transaction-manager="transactionManager"/>
<bean id="dataSource" . . ./>
<bean id="transactionManager" . . ./>
<batch:job id="samplejob" job-repository="jobRepository">
. . .
</batch:job>
Spring Batch에서는 Item을 읽고 쓰는 API들을 ItemReader, ItemWriter 인터페이스로 추상화해서 제공하고 있습니다.
ItemReader는 여러 종류의 데이터 타입을 입력 받을 수 있습니다.
기본적인 ItemReader 인터페이스는 아래와 같다.
public interface ItemReader<T> {
T read() throws Exception, UnexpectedInputException, ParseException;
}
read() 메소드는 ItemReader의 필수적인 메소드이며 결과값으로 하나의 item을 반환하고 더이상 반환할 item이 없을 경우 null을 반환합니다.
item은 플랫 파일에서의 한 라인, 데이터베이스에서의 한 행, XML 파일에서의 엘리먼트를 나타냅니다.
ItemWriter의 기능은 ItemReader와 유사하지만 정반대의 동작을 합니다. 기본적인 ItemWriter 인터페이스는 아래와 같다.
public interface ItemWriter<T> {
void write(List<? extends T> items) throws Exception;
}
write() 메소드는 ItemWriter의 필수적인 메소드이며 인자로 건넨 객체가 열려 있는 동안 쓰기 작업을 시도합니다.
Glue에서는 ApplicationContext 설정을 통해서 Spring Batch기능을 사용할 수 있습니다.
설정하는 XML파일은 Glue에서 기본으로 사용하는 applicationContext.xml파일을 사용하거나 별도의 XML파일에서 Spring Batch 설정을 할 수도 있습니다.
아래 예와 같이 Spring 에서는 Spring Batch 설정을 지원하기 위해서 전용 XML 네임스페이스를 제공하는 태그( <batch> )를 기반으로 하고 있습니다. 전용 네임스페이스가 제공하는 태그를 사용하면 Spring Batch 내부의 상세 구현내용을 감추면서 Job, Step, JobRepository 와 같은 핵심 컴포넌트를 쉽게 설정할 수 있고 Batch처리의 동작방식을 정의하거나 커스터마이징이 가능합니다.
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:batch="http://www.springframework.org/schema/batch"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.2.xsd
http://www.springframework.org/schema/batch
http://www.springframework.org/schema/batch/spring-batch-3.0.xsd">
<bean id="serviceManager" class="com.poscoict.glueframework.biz.control.GlueServiceManagerImpl">
<property name="serviceLoader" ref="serviceLoader" />
<property name="cacheManager" ref="cacheManager" />
</bean>
<bean id="cacheManager" . . . />
<bean id="serviceLoader" . . . />
<bean id="jobLauncher" . . ./>
<batch:job-repository />
<bean id="dataSource" . . ./>
<bean id="transactionManager" . . ./>
<batch:job id="job">
<batch:step id="step">
<batch:tasklet>
<batch:chunk reader="reader" processor="bizProcessor" writer="writer" commit-interval="1000" />
</batch:tasklet>
</batch:step>
</batch:job>
<bean id="bizProcessor" . . . />
<bean id="reader" . . . />
<bean id="writer" . . . />
</beans>
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.2.xsd">
<import resource="biz_batch.xml"/>
<bean id="serviceManager" class="com.poscoict.glueframework.biz.control.GlueServiceManagerImpl" lazy-init="true">
<property name="serviceLoader" ref="serviceLoader" />
<property name="cacheManager" ref="cacheManager" />
</bean>
<bean id="cacheManager" . . . />
<bean id="serviceLoader" . . . />
</beans>
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:batch="http://www.springframework.org/schema/batch"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.2.xsd
http://www.springframework.org/schema/batch
http://www.springframework.org/schema/batch/spring-batch-3.0.xsd">
<bean id="jobLauncher" . . ./>
<batch:job-repository />
<bean id="dataSource" . . ./>
<bean id="transactionManager" . . ./>
<batch:job id="job">
<batch:step id="step">
<batch:tasklet>
<batch:chunk reader="reader" processor="bizProcessor" writer="writer" commit-interval="1000" />
</batch:tasklet>
</batch:step>
</batch:job>
<bean id="bizProcessor" . . . />
<bean id="reader" . . . />
<bean id="writer" . . . />
</beans>
Spring Batch에서 제공하는 ItemReader, ItemWriter 외에도 Glue 에서도 ItemReader와 ItemWriter가 있습니다.
Glue Framework에 특화된 GlueCursorItemReader, GlueJdbcBatchItemWriter 도 있으며, applicationContext 설정을 최소화한 GlueDefaultItemReader, GlueDefaultItemWriter 도 있습니다.
Glue 에서는 Item이 DB 일 경우 읽기 쓰기가 가능한 GlueCursorItemReader 와 GlueJdbcBatchItemWriter 를 제공합니다.
Batch에서는 대용량 데이터를 다루어야 하는 경우가 많은데 이럴 경우 일반적인 메커니즘에서는 해당 데이터를 한번에 메모리에 올리기 때문에 문제가 발생할 수 있습니다.
Spring Batch에서는 이 문제를 해결하기 위해 Cursor기반의 JdbcCursorItemReader 를 제공하고 있습니다.
Glue에서는 Glue의 쿼리 파일을 사용할 수 있도록 GlueCursorItemReader 를 제공하고 있습니다.
JdbcCursorItemReader 는 SQL문을 설정파일에 작성하지만 GlueCursorItemReader는 주어진 query id를 통해 SQL문을 제공합니다.
GlueCursorItemReader 의 상속관계 및 메소드는 Java Doc을 참고합니다 (GlueAPI).
GlueCursorItemReader 의 필수 속성(property)는 다음과 같습니다.
<beans . . .>
<bean id="biz-dataSource" . . . />
<bean id="queryManager" . . . />
<bean id="reader" class="com.poscoict.glueframework.batch.item.GlueCursorItemReader">
<property name="dataSource" ref="biz-dataSource" />
<property name="queryManager" ref="queryManager" />
<property name="queryId" value="select.emp" />
<property name="rowMapper" ref="empRowMapper" />
</bean>
<bean id="empRowMapper" . . . />
. . .
Spring Batch 에서는 데이터베이스와 연동해서 Item 쓰기 역할을 하는 JdbcBatchItemWriter를 제공하고 있습니다.
Glue에서는 Glue의 쿼리 파일을 사용할 수 있도록 GlueJdbcBatchItemWriter를 제공하고 있습니다. JdbcBatchItemWriter 는 SQL문을 설정파일에 작성하지만 GlueJdbcBatchItemWriter는 주어진 query id를 통해 SQL문을 제공합니다.
GlueJdbcBatchItemWriter 의 상속관계 및 메소드는 Java Doc을 참고합니다 (GlueAPI).
GlueJdbcBatchItemWriter 의 필수 속성(property)는 다음과 같습니다.
그리고 queryId에 해당하는 SQL문의 특성에 따라 추가 속성(property) 를 설정합니다.
<beans . . .>
<bean id="biz-dataSource" . . . />
<bean id="queryManager" . . . />
<bean id="writer" class="com.poscoict.glueframework.batch.item.GlueJdbcBatchItemWriter">
<property name="dataSource" ref="dataSource" />
<property name="queryManager" ref="queryManager" />
<property name="queryId" value="insert.emp" />
<property name="assertUpdates" value="true" />
<property name="itemSqlParameterSourceProvider">
<bean class="org.springframework.batch.item.database.BeanPropertyItemSqlParameterSourceProvider" />
</property>
</bean>
. . .
ItemReader, ItemWriter는 그 목적에 따라 설정해야할 것들이 많습니다. / Glue에서는 이러한 설정을 최소화한 GlueDefaultItemReader와 GlueDefaultItemWriter를 제공합니다.
그리고 필요한 정보는 JobParameter를 통해 제공합니다.
String stepId = "step"; JobParametersBuilder builder = new JobParametersBuilder(); builder.addString( stepId + ".reader.resource.type", "jdbcDb" ); builder.addString( stepId + ".reader.sql", "select * from emp" ); JobParameters jobParameters = builder.toJobParameters();
해당 Job의 어떤 Step에서 사용하는 Parameter 정보인지를 구분하기 위해서 Key앞에 Step ID를 붙여서 구분합니다.
GlueDefaultItemReader는 JobParameter에 따라 org.springframework.batch.item.file.FlatFileItemReader 또는 org.springframework.batch.item.database.JdbcCursorItemReader 를 생성합니다.
GlueDefaultItemReader 의 상속관계 및 메소드는 Java Doc을 참고합니다 (GlueAPI).
<beans . . .>
<bean id="biz-dataSource" . . . />
<bean id="reader" class="com.poscoict.glueframework.batch.item.GlueDefaultItemReader" />
<bean id="writer" . . . />
<bean id="bizProcessor" . . . />
<batch:job id="job">
<batch:step id="step">
<batch:tasklet>
<batch:chunk reader="reader" processor="bizProcessor" writer="writer" commit-interval="1000" />
</batch:tasklet>
</batch:step>
</batch:job>
. . .
GlueDefaultItemReader 의 JobParameter는 다음과 같은 것이 있습니다.
builder.addString( stepId + ".reader.resource.name", "/emp-input.txt" );
builder.addString( stepId + ".reader.field.names", "empno,ename,deptno" );
builder.addString( stepId + ".reader.vo.type", "sample.vo.EmpVO" );
<query id="emp.select" desc="" resultType="sample.vo.EmpVO" isNamed="false">
<![CDATA[
select EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, DEPTNO
from EMP
]]>
</query>
builder.addString( stepId + ".reader.delimiter", "," );
builder.addString( stepId + ".reader.columns", "1-10,11-20,21-30" );
builder.addString( stepId + ".reader.sql", "select * from emp" );
<beans . . .>
<bean id="biz-dataSource" . . . />
<bean id="reader" class="com.poscoict.glueframework.batch.item.GlueDefaultItemReader">
<property name="dataSource" ref="biz-dataSource" />
</bean>
. . .
builder.addString( stepId + ".reader.query.id", "emp.select" );
<beans . . .>
<bean id="biz-dataSource" . . . />
<bean id="queryManager" . . . />
<bean id="reader" class="com.poscoict.glueframework.batch.item.GlueDefaultItemReader">
<property name="dataSource" ref="biz-dataSource" />
<property name="queryManager" ref="queryManager" />
</bean>
. . .
GlueDefaultItemWriter는 JobParameter에 따라 org.springframework.batch.item.file.FlatFileItemWriter 또는 org.springframework.batch.item.database.JdbcBatchItemWriter 를 생성합니다.
GlueDefaultItemWriter 의 상속관계 및 메소드는 Java Doc을 참고합니다 (GlueAPI).
<beans . . .>
<bean id="biz-dataSource" . . . />
<bean id="reader" . . . />
<bean id="writer" class="com.poscoict.glueframework.batch.item.GlueDefaultItemWriter" />
<bean id="bizProcessor" . . . />
<batch:job id="job">
<batch:step id="step">
<batch:tasklet>
<batch:chunk reader="reader" processor="bizProcessor" writer="writer" commit-interval="1000" />
</batch:tasklet>
</batch:step>
</batch:job>
. . .
GlueDefaultItemWriter 의 JobParameter는 다음과 같은 것이 있습니다.
builder.addString( stepId + ".writer.resource.name", "/output/emp.out" );
builder.addString( stepId + ".writer.field.names", "user_id,user_nm,dept_id" );
builder.addString( stepId + ".writer.field.format", "%-30s%-30s%-10s" );
builder.addString( stepId + ".writer.field.delimiter", "," );
builder.addString( stepId + ".writer.sql", "insert into tb_users(user_id,user_nm,dept_id) values(:user_id,:user_nm,:dept_id)" );
<beans . . .>
<bean id="biz-dataSource" . . . />
<bean id="queryManager" . . . />
<bean id="writer" class="com.poscoict.glueframework.batch.item.GlueDefaultItemWriter">
<property name="dataSource" ref="biz-dataSource" />
</bean>
. . .
builder.addString( stepId + ".writer.query.id", "users.insert" );
<beans . . .>
<bean id="biz-dataSource" . . . />
<bean id="queryManager" . . . />
<bean id="writer" class="com.poscoict.glueframework.batch.item.GlueDefaultItemWriter">
<property name="dataSource" ref="biz-dataSource" />
<property name="queryManager" ref="queryManager" />
</bean>
. . .
Job을 실행시키기 위해서는 JobLauncher가 필요합니다.
이미 언급했듯, Spring Batch는 Scheduler가 아니기 때문에, Quartz 등을 통해 JobLauncher를 이용해서 Job을 실행시키는 구조가 될 것입니다.
다음은 Job를 테스트할 수 있는 소스 일부입니다.
import org.springframework.batch.core.Job;
import org.springframework.batch.core.JobParameters;
import org.springframework.batch.core.launch.JobLauncher;
import com.poscoict.glueframework.context.GlueStaticContext;
public class TestJob {
public static void main( String arg[] ) throws Exception {
JobLauncher jobLauncher
= GlueStaticContext.getBeanFactory().getBeanObject( "jobLauncher", JobLauncher.class );
Job job
= GlueStaticContext.getBeanFactory().getBeanObject( "sampleJob", Job.class );
JobParameters params = . . .
jobLauncher.run( job, params );
}
}
<beans . . .>
<bean id="jobLauncher" class="org.springframework.batch.core.launch.support.SimpleJobLauncher">
<property name="jobRepository" ref="jobRepository"/>
</bean>
<batch:job-repository />
<bean id="dataSource" . . ./>
<bean id="transactionManager" . . ./>
<batch:job id="sampleJob">
<batch:step id="step" . . . />
</batch:job>
. . .
위 예제와 같이 Glue에서는 Quartz에서 Job를 실행할 수 있는 GlueQuartzJobLauncher(JobDetail) 와 GlueService 에서 Job를 실행할 수 있는 GlueJobLaunch(GlueActivity) 가 있습니다.
Quartz Job Scheduler 를 사용하는 환경에서 GlueQuartzJobLauncher 는 다음과 같이 사용합니다.
<beans . . .>
. . .
<bean id="jobDetail-job" class="org.springframework.scheduling.quartz.JobDetailBean">
<property name="jobClass" value="com.poscoict.glueframework.batch.quartz.GlueQuartzJobLauncher"/>
<property name="jobDataAsMap">
<map>
<entry key="JobName" value="sampleJob"/>
<entry key="JobLauncherName" value="jobLauncher"/>
</map>
</property>
</bean>
. . .
그외 Glue Service 에서 Activity layer에서 Job을 실행 할 수 있는 GlueJobLaunch 는 다음과 같이 사용합니다.
<service . . .>
. . .
<activity name="JobLauncher" class="com.poscoict.glueframework.batch.activity.GlueJobLaunch">
<property name="job" value="sampleJob" />
<property name="launcher" value="jobLauncher" />
<transition . . . />
</activity>
. . .
