| 목차 >> Hadoop & HBase -- Hadoop +- Hive ----+- Glue기반 Hive 사용 +- HBase ----+- Glue기반 Hbase 연동 +- Phoenix ----+- Glue기반 Phoenix & GlueJdbcDao +- Impala ----+- Glue기반 Impala & GlueJdbcDao |
Glue Framework에서 제공하는 Hadoop & HBase 관련 기능들은 Spring 기반에서 개발 되었으며 해당 기능들의 원활한 적용을 위해서는 Spring 에 대한 기본적인 이해가 반드시 필요합니다.
본 문서에서도 Spring 에 대해서 기술하고 있지만 기본적인 내용만 기술하고 있으므로 보다 자세한 내용이 알고 싶을 경우에는 관련 사이트(예: http://projects.spring.io/) 를 참고하도록 합니다.
아파치 하둡(Apache Hadoop, High-Availability Distributed Object-Oriented Platform)은 대량의 자료를 처리할 수 있는 큰 컴퓨터 클러스터에서 동작하는 분산 응용 프로그램을 지원하는 프리웨어 자바 소프트웨어 프레임워크입니다. 원래 너치의 분산 처리를 지원하기 위해 개발된 것으로, 아파치 루씬의 하부 프로젝트입니다. 분산처리 시스템인 구글 파일 시스템을 대체할 수 있는 하둡 분산 파일 시스템(HDFS: Hadoop Distributed File System)과 맵리듀스를 구현한 것입니다.
Hadoop의 기능을 간단하게 설명하면 분산 파일 시스템 형태로 용량을 확장할 수 있는 파일 시스템인 HDFS에 데이터를 저장하고, 이렇게 저장된 데이터를 바탕으로 MapReduce 연산을 실행해 원하는 데이터를 얻어내는 것입니다.
Hadoop의 기본 개념은 HDFS와 MapReduce인데 Glue Framework와 관련이 있는 부분은 저장된 데이터를 가져오는 MapReduce 개념입니다.
MapReduce는 일종의 함수형 프로그래밍입니다. map, reduce라는 합쳐진 용어로, 두 함수의 조합을 통해서 분산/병렬 시스템을 운용을 지원합니다.
맵 함수의 입력으로 키(k1), 값(v1)이 전달 되면, 맵 함수는 전달된 키-값을 이용해 사용자의 로직을 처리(이미 구현된 map이 있지만, 사용자가 구현도 가능하다)한다.
대용량 데이터의 대한 분산 처리를 하기 위해서는 사용자가 자기 입맛에 맞게 구현을 해야 한다. 구현한 후 출력으로 새로운 키(k2)와 값(v2)의 목록을 출력 한다.
이 때 키-값이 그대로 출력될 수 있으며, 출력 데이터의 갯수는 0 또는 1개 이상 일 수 있다.
맵 함수가 반복 적으로 수행 되면 여러 개의 출력 데이터가 생성 되고, 이 출력 데이터를 키로 정렬하면 각 키에 여러 개의 데이터가 존재 한다.
이 키(k2)와 값 목록(list(v2))이 리듀스 함수로 입력 된다. 리듀스 함수는 키-값 목록을 파라미터로 받아 사용자의 로직을 처리한 후 여러 개의 값을 출력 한다.
| 그림 : MapReduce |
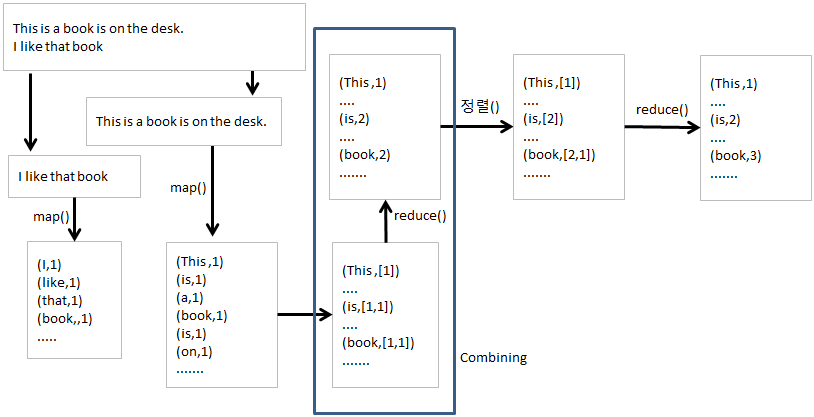
WordCount 예제
MapReduce 예제로 가장 많이 사용되는 단어 개수를 세는 예제를 이용해서 MapReduce의 대해 알아 보자.
맵리듀스가 분산/병렬 처리하기 좋은 이유는 입력 데이터에 대한 맵 함수는 동시에 독립적으로 병렬 처리할 수 있는 구조 이기 때문이다.
위의 예제를 Line 1, 2 를 각각의 서버에서 실행되면 단순 계산상으로 2배의 성능효과를 볼 수 있다.
하이브는 하둡 기반의 데이터 웨어하우징 프레임워크다.
페이스북의 급증하는 소셜네트워킹에서 매일 생성되는 대량의 데이터를 관리 하고, 학습 하기 위해 개발되었다.
페이스북에서는 대량의 데이터를 HDFS에 저장한 후, HiveQL (하이브가 제공하는 SQL)을 이용해서 데이터를 분석한다.
HiveQL과 같이 SQL을 사용하는 방식이 모든 빅데이터 문제에 이상적인 해결책은 아지만, 대다수의 경우에는 데이터 분석에 상당히 효과적이다.
일반적으로 하이브는 로컬 머신에서 사용하는데, 사용자는 HiveQL을 작성한 후 실행하면, 하이브는 해당 질의문을 맵리듀스 Job으로 변환하여 하둡 클러스터에서 구동시킨다.
하이브는 데이터를 테이블 형태로 표현한다.
HDFS에 저장된 데이터와 테이블 스키마 사이에서, 하이브가 매개체 역할을 한다.
테이블 스키마와 같은 메타데이터는 메타스토어(metastore) 에 저장된다.
Spring HIVE 예제
| 그림 : HIVE |
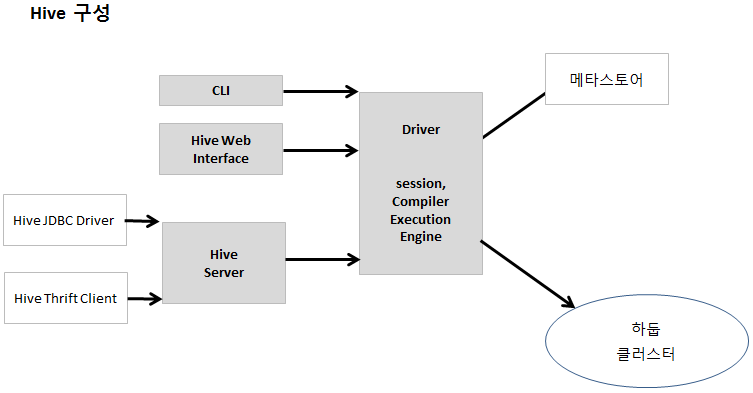
Hive Server의 기동
Bean 설정은 아래와 같다. 실제 Spring 제공 예제에서는 로컬에 설치된 Hadoop과의 연동이 불안정해서 별동로 설치된 Hive 서버를 기동시켜서 테스트 하였다.
<hive-server port="${hive.port}" auto-startup="true"
properties-location="hive-server.properties"/>
Thrift Client 를 이용한 Hive Script의 수행
Bean 설정은 아래와 같다.
<hdp:hive-client-factory host="some-other-host" port="10001" /> <hdp:hive-runner id=”hiveRunner”hive-client-ref=”hiveClientFactory” run-at-startup=”false” pre-action=”hdfsScript”> <script location=”password-analysis.hal”/> </hdp:/hiverunner>
HiveRunner 사용하는 Java 소스는 아래를 참고한다.
AbstractApplicationContext context = new ClassPathXmlApplicationContext("/META-INF/spring/hive-apache-log-context.xml", HiveAppWithApacheLogs.class);
log.info("Hive Application Running");
context.registerShutdownHook();
HiveRunner runner = context.getBean(HiveRunner.class);
runner.call();
HiveClient이용
HiveClient hiveClient = hiveClientFactory.getHiveClient();
hiveClient.execute("select count(*) from passwords");
HiveOperations 이용(구현체로 HiveTemplate 제공)
hiveOperations.queryForLong("select count(*) from " + tableName);
Map parameters = new HashMap();
parameters.put("inputFile", inputFile);
hiveOperations.query("classpath:password-analysis.hql", parameters);
JDBC 드라이버 이용
<bean id="hive-driver" class="org.apache.hadoop.hive.jdbc.HiveDriver"/>
<bean id="hive-ds" class="org.springframework.jdbc.datasource.SimpleDriverDataSource"
c:driver-ref="hive-driver"
c:url="url...."/>
<bean id=" jdbcTemplate" class="org.springframework.jdbc.core.JdbcTemplate"
c:data-source-ref="hive-ds"/>
JdbcTemplate 을 사용하는 Java 소스는 아래를 참고한다.
JdbcTemplate jdbcTemplate = (JdbcTemplate) context.getBean("jdbcTemplate");
jdbcTemplate.queryForInt("select count(*) from passwords");
Spring Batch와 연동
<hdp:hive-tasklet id="hive-script">
<hdp:script>
DROP TABLE IF EXITS testHiveBatchTable;
CREATE TABLE testHiveBatchTable (key int, value string);
</hdp:script>
<hdp:script location="classpath:org/company/hive/script.q" />
</hdp:hive-tasklet>
현재 Glue에서 사용하고 있는 Spring 버전은 3.2.8인데 Spring Hadoop 2.1.0.RELEASE와 기본적으로 연동되는 Spring 버전은 4.0.5이다. 하지만 3.2.8에서 HiveTemplate을 비롯한 기본 기능을 테스트 해 본 결과 정상적으로 동작하는 것은 확인하였다.
현재 상태에서도 Datasource에서 HiveDriver를 사용하면 GlueJdbcDao를 이용하여 쿼리를 실행할 수 있다.
<bean id="hiveDriver" class="org.apache.hadoop.hive.jdbc.HiveDriver"/>
<bean id="test-dataSource" class="org.springframework.jdbc.datasource.SimpleDriverDataSource">
<constructor-arg name="driver" ref="hiveDriver"/>
<constructor-arg name="url" value="jdbc:hive://localhost:10000"/>
</bean>
<bean id="test-tx" class="com.poscoict.glueframework.transaction.GlueDataSourceTransactionManager">
<property name="dataSource" ref="test-dataSource"/>
</bean>
<bean id="test-dao" class="com.poscoict.glueframework.dao.jdbc.GlueJdbcDao">
<property name="dataSource" ref="test-dataSource"/>
<property name="queryManager" ref="queryManager"/>
<property name="batchUpdateLimit" value="30000"/>
</bean>
위와같이 datasource가 등록되어 있고 Java에서 Hive 기반 쿼리를 실행하고 싶을 경우 다른 DB의 쿼리를 실행시키는 것처럼 xxx-query.glue_sql 파일에 해당 쿼리를 등록하고 아래와 같은 방식으로 실행 시키면 된다.
GlueGenericDao dao = (GlueGenericDao)GlueStaticContext.getBeanFactory().getBeanObject("test-dao");
List list = dao.find("sample.pass.select");
Hive 에서 사용되는 HiveQL의 문법은 oracle 과 같은 다른 DB의 문법과 다른 부분이 있으므로 해당 쿼리의 문법은 Hive 매뉴얼을 참고하도록 한다.
| 그림 : 출처 - http://www.larsgeorge.com/2009/10/hbase-architecture-101-storage.html |
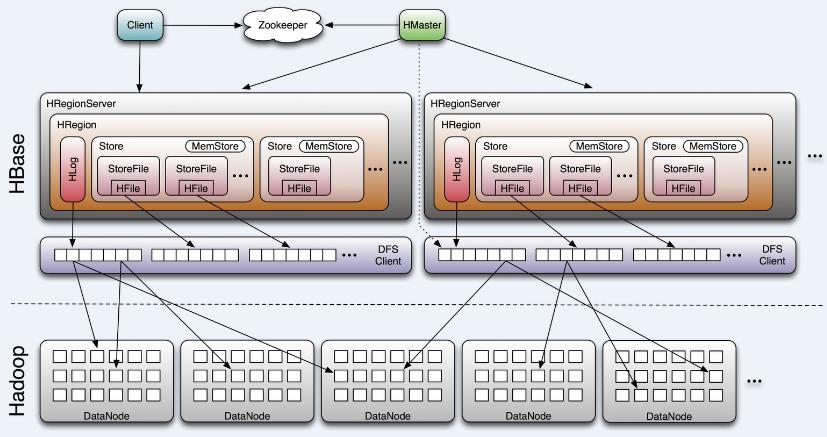
아파치 HBase(Apache HBase)는 하둡 플랫폼을 위한 공개 비관계형 분산 데이터 베이스이다. 구글의 빅테이블(BigTable)을 본보기로 삼았으며 자바로 쓰여졌다. 아파치 소프트웨어 재단의 아파치 하둡 프로젝트 일부로서 개발되었으며 하둡의 분산 파일 시스템인 HDFS위에서 동작을 한다. 대량의 흩어져 있는 데이터 저장을 위한 무정지 방법을 제공하는 구글의 빅테이블과 비슷한 기능을 한다.
HBase는 압축, 인메모리 처리, 초기 빅테이블에 제시되어 있는 Bloom 필터 기능을 제공한다. HBase에 있는 테이블들은 하둡에서 동작하는 맵리듀스 잡들을 위한 입력, 출력을 제공하며 자바 API나 REST, Avro 또는 Thrift 게이트웨이를 통하여 접근할 수 있다.
HBase는 기존의 SQL 데이터 베이스를 직접적으로 대체하지는 않지만 페이스북의 메시징 플랫폼과 같은 데이터를 많이 사용하는 웹사이트에서 사용된다.
HBase 데이터 모델의 주요 특징은 아래와 같다.
| 그림 : 테이블구조 |
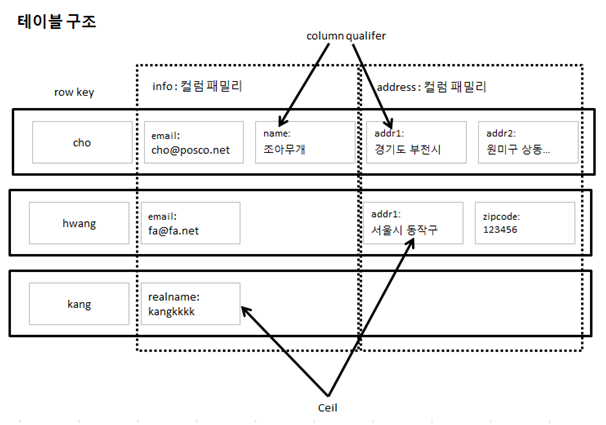
Hbase & Java 연동
Java 기반에서 Hbase에 연동하기 위해서 Hbase에서는 Client API를 제공하고 있다.
데이터를 입력하기 위해서는 Put, 삭제하기 위해서는 Delete 클래스를 사용하며 데이터 조회를 위해서는 Scan 클래스를 사용한다.
조건을 가지고 조회하기 위해서는 Filter 클래스가 필요한데 사용하는 방법은 아래와 같다.
Configuration config = (Configuration) context.getBean("hbaseConfiguration");
HTable table = new HTable(config, "users");
Scan scan = new Scan();
scan.addFamily(CF_INFO);
Filter filter1 = new SingleColumnValueFilter(CF_INFO,Bytes.toBytes("user"),CompareOp.EQUAL,Bytes.toBytes("user02"));
Filter filter2 = new SingleColumnValueFilter(CF_INFO,Bytes.toBytes("email"),CompareOp.EQUAL,Bytes.toBytes("email@01"));
Filter filter = new FilterList(FilterList.Operator.MUST_PASS_ONE,Arrays.asList(filter1,filter2));
scan.setFilter(filter);
ResultScanner scanner = table.getScanner(scan);
for (Result result = scanner.next(); result != null; result = scanner.next())
System.out.println("row : " + result);
scanner.close();
Spring 기반 HBASE 연동
Spring에서는 Spring data hadoop hbase프로젝트를 통해서 Hbase 연동 기능을 제공하고 있다.
Spring 기반에서 Hbase와 연동하기 위해서는 HbaseTemplate이 필요한데 HbaseTemplate은 hbase-configuration이 필요하므로 Xml기반에서 Bean으로 등록할 경우 아래와 같은 설정이 필요하다
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:hdp="http://www.springframework.org/schema/hadoop"
xmlns:p="http://www.springframework.org/schema/p"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/hadoop http://www.springframework.org/schema/hadoop/spring-hadoop.xsd">
. . .
<hdp:configuration id="hadoopConfiguration">
</hdp:configuration>
<hdp:hbase-configuration delete-connection="false" configuration-ref="hadoopConfiguration" zk-quorum="0.0.0.0" zk-port="2181"/>
<bean id="hbaseTemplate" class="org.springframework.data.hadoop.hbase.HbaseTemplate">
<property name="configuration" ref="hbaseConfiguration"/>
</bean>
</beans>
byte[] cfInfo = Bytes.toBytes("cfInfo");
Configuration config = (Configuration) context.getBean("hbaseConfiguration");
HBaseAdmin admin = new HBaseAdmin(config);
HTableDescriptor tableDescriptor = new HTableDescriptor("users");
HColumnDescriptor columnDescriptor = new HColumnDescriptor(cfInfo);
tableDescriptor.addFamily(columnDescriptor);
admin.createTable(tableDescriptor);
template.execute("users", new TableCallback<User>() {
public User doInTable(HTableInterface table) throws Throwable {
User user = new User("test", "email", "password");
Put p = new Put(Bytes.toBytes(user.getName()));
p.add(CF_INFO, qUser, Bytes.toBytes(user.getName()));
p.add(CF_INFO, qEmail, Bytes.toBytes(user.getEmail()));
p.add(CF_INFO, qPassword, Bytes.toBytes(user.getPassword()));
table.put(p);
return user;
}
});
List result = template.find("users", "cfInfo", new RowMapper<User>() {
@Override
public User mapRow(Result result, int rowNum) throws Exception {
return new User(Bytes.toString(result.getValue(CF_INFO, qUser)),
Bytes.toString(result.getValue(CF_INFO, qEmail)),
Bytes.toString(result.getValue(CF_INFO, qPassword)));
}
});
Glue framework에서는 Hbase와 연동을 위해서 HbaseTemplate 기반에서 동작하는 Dao Class(GlueHbaseDao) 와 Reuse Active를 제공하고 있다.
GlueHbaseDao의 상속관계 및 메소드는 Java Doc을 참고합니다 (GlueAPI).
GlueHbaseDao를 사용하기 위해서는 applicationContext.xml에 GlueHbaseDao를 Bean으로 등록하여야 하며 GlueHbaseDao가 동작하기 위해서는 Hbase 연결 정보를 가진 hbase-configuration가 꼭 필요하다.
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:hdp="http://www.springframework.org/schema/hadoop"
xmlns:p="http://www.springframework.org/schema/p"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/hadoop http://www.springframework.org/schema/hadoop/spring-hadoop.xsd">
<hdp:configuration id="hadoopConfiguration" />
<hdp:hbase-configuration delete-connection="false" zk-quorum="0.0.0.0" zk-port="2181"/>
<bean id="hbaseTemplate" class="org.springframework.data.hadoop.hbase.HbaseTemplate">
<property name="configuration" ref="hbaseConfiguration"/>
</bean>
<bean id="hbaseDao" class="com.poscoict.glueframework.dao.hbase.GlueHbaseDao">
<property name="hbaseTemplate" ref="hbaseTemplate"/>
</bean>
...
GlueHbaseDao에서는 Hbase에서 데이터를 가져오기 위해서 find 메서드를 제공하고 있다.
GlueHbaseDao에서는 Hbase에서 데이터를 저장하기 위해서 save 메서드를 제공하고 있다.
GlueHbaseDao에서는 Hbase에서 데이터를 삭제하기 위해서 delete 메서드를 제공하고 있다.
GlueHbaseDao를 이용하는 reuse activity는 다음과 같은 것을 제공하고 있다. 각 Activity의 Property는 javadoc을 확인합니다.
흔히 HBase용 SQL 스킨(SQL skin for HBase)'라고 일컫는다.
높은 성능과 읽기/쓰기 작업을 위해, 내장된 JDBC 드라이버를 통해 SQL 같은 명령어로 HBase 쿼리를 처리하는 방법이다.
HBase를 이용하는 사람들이라면 쉽게 도입해 활용할 수 있다. 오픈소스이고, 벌크 데이터 불러오기 등 유용한 기능을 갖추고 있기 때문이다.
Hbase가 적용되면서 가장 크게 이슈가 되고 있는 부분은 Read Performance를 높이는 것이다.
그리고 Client에서 java로 Hbase에 접근할 경우 전체 데이터를 가져오는 경우에는 간단하지만 Scan 조건이 복잡할 경우 Client 프로그램도 매우 복잡해서 개발 리소스가 많이 필요한 경우가 대부분이다.
Phoenix는 기존에 쓰던 JDBC, SQL을 그대로 HBase에서 사용 할 수 있도록 지원한다.
예를들어 ‘김씨가 2002년에 발생한 책을 찾아라’는 명령을 수행하기 위해서 아래와 같이 간단한 SQL로 해결 가능하다
SELECT * FROM book WHERE author="kim" AND year = 2002
여기에서 추가로 성능 향상을 위해서 아래와 같은 다양한 최적화 기능을 지원하고 있다.
Hbase에서 Phoenix를 사용하기 위한 기본 설정은 아래와 같다.
<property>
<name>hbase.regionserver.wal.codec</name>
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value>
</property>
Connection conn;
Properties prop = new Properties();
Class.forName("org.apache.phoenix.jdbc.PhoenixDriver");
System.out.println("##################################################");
conn = DriverManager.getConnection("jdbc:phoenix:0.0.0.0:2181");
System.out.println("###################################################");
conn.createStatement().executeUpdate("UPSERT into us_population values('30','bubu',5000)");
conn.commit();
ResultSet rst = conn.createStatement().executeQuery("select * from us_population");
while (rst.next()) {
System.out.println("#######"+rst.getString(1) +":"+rst.getString(2) + ":" +rst.getString(3));
}
Pheonix에서 Hbase와 연동할 수 있는 jdbc Driver Class를 제공하고 있기 때문에 Pheonix를 이용하면 GlueJdbcDao Class를 이용하여 Hbase와 연동이 가능하다.
| 그림 : Phoenix & GlueJdbcDao |
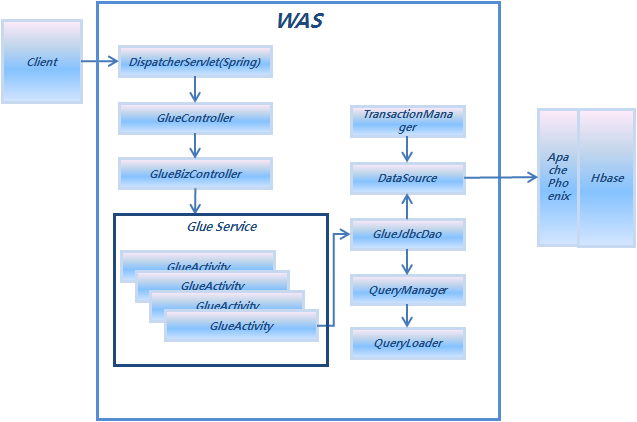
<bean id="test-dataSource" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="org.apache.phoenix.jdbc.PhoenixDriver"/>
<property name="url" value="jdbc:phoenix:0.0.0.0:2181"/>
</bean>
<bean id="test-tx" class="com.poscoict.glueframework.transaction.GlueDataSourceTransactionManager">
<property name="dataSource" ref="test-dataSource"/>
</bean>
<bean id="test-dao" class="com.poscoict.glueframework.dao.jdbc.GlueJdbcDao">
<property name="dataSource" ref="test-dataSource"/>
<property name="queryManager" ref="queryManager"/>
<property name="batchUpdateLimit" value="30000"/>
</bean>
GlueJdbcDao Class의 find메서드를 이용하여 데이터의 Search가 가능하다. Named 쿼리와 결과 값으로 VO 객체의 맵핑 모두 가능하다.
List<Object> list = new ArrayList<Object>();
list.add( 30 );
GlueParameter<List<Object>> listParam = new GlueParameter<List<Object>>();
listParam.setParameter( list );
//일반 쿼리에서 Serch, 결과값 Map
List<Map> uslist = dao.find("sample.emp.select",listParam);
//일반 쿼리에서 Serch , 결과값 VO객체
List<EmpVO> uslist2 = dao.find("sample.emp.select.vo",listParam);
Map<String,Object> map = new HashMap<String,Object>();
map.put("deptno", 30 );
GlueParameter<Map<String,Object>> mapParam = new GlueParameter<Map<String,Object>>();
mapParam.setParameter( map );
//Named 쿼리에서 Serch, 결과값 Map
uslist = dao.find("sample.emp.select.named",mapParam);
// Named 쿼리에서 Serch , 결과값 VO객체
uslist2 = dao.find("sample.emp.select.named.vo",mapParam);
GlueJdbcDao Class의 insert메서드를 이용하여 데이터의 Save가 가능하다.
GlueGenericDao dao = (GlueGenericDao)GlueStaticContext.getBeanFactory().getBeanObject("test-dao");
List<Object> insertlist = new ArrayList<Object>();
insertlist.add( 3 );
insertlist.add( "test3" );
insertlist.add( 9000 );
insertlist.add( 30 );
GlueParameter<List<Object>> insertParam = new GlueParameter<List<Object>>();
insertParam.setParameter( insertlist );
dao.insert("sample.emp.upsert", insertParam);
phoenix에서는 update, insert 구문이 없고 UPSERT만 존재하므로 쿼리 작성에 유의 하여야 한다.
UPSERT into emp(empno, ename, sal, deptno) values (?, ?, ?, ?)
GlueJdbcDao Class의 delete메서드를 이용하여 데이터의 Delete가 가능하다.
List<Object> dellist = new ArrayList<Object>();
dellist.add( 3 );
GlueParameter<List<Object>> deleteParam = new GlueParameter<List<Object>>();
deleteParam.setParameter( dellist );
dao.delete("sample.emp.delete", deleteParam);
다른 JDBC 드라이버를 사용 할때와 다른 점으로는 바인딩되는 값의 자동 형변환이 되지 않는다. 예를 들어 아래와 같이 Integer 타입에 String 값을 바인딩 해도 ojdbc의 경우에는 자동 형변환되어 에러가 발행하지 않지만 PhoenixDriver에서는 에러가 발생한다.
List<Object> list = new ArrayList<Object>();
list.add( "30" ); //실행 바인딩해야 할 값은 Integer이므로 Integer 변환하여야 에러가 발생하지 않는다.
GlueParameter<List<Object>> listParam = new GlueParameter<List<Object>>();
listParam.setParameter( list );
List<Map> uslist = dao.find("sample.emp.select",listParam);
또한 ojdbc의 경우에는 동일 트랜잭션에서 Insert 했을 경우 Commit 전에 조회를 하면 Insert 한 결과가 포함되어 조회되지만 Phoenix에서는 동일 트랜잭션이라도 Commit전에 조회를 하면 해당 결과가 반영되지 않는다.
그 외에도 기본적인 문법에서도 다른 부분이 있으므로 자세한 내용은 http://phoenix.apache.org 을 참고하도록 한다.
클라우드데라(Cloudera) Impala는 HDFS, Hbase, Amazon Simple Storage Service(S3) 의 아파치 하둡 데이터 저장된 데이터을 실시간 질의를 가능하게 하는 서비스 입니다.
이와 같은 메타 데이터와 Apache Hive로 ODBC , JDBC드라이버와 Hive Standard Query Langeage (HiveQL)에 기반으로 한 쿼리 언어를 지원합니다.
지연을 방지하기 위해서, MapReduce을 사용하지 않고Impala는 직접 상용 병렬 RDMS에서 사용 쿼리와 유사한 분산 쿼리 엔진을 통해 데이터를 액세스 합니다.
| 그림 : 아키텍처 출처 - http://www.cloudera.com/ |
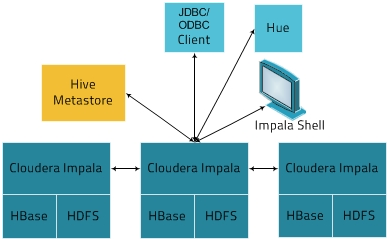
Hive Metastore : impala에서 사용 가능한 데이터에 대한 정보을 저장
예를 들면 어떤 데이터베이스을 사용하고 그 구조가 어떻게 되는지에 대한 정보.
Impala의 JDBC연동을 위한 라이브러리는 다음과 같습니다. Client에서 자바 및 타 프로그램의 Languages을 이용에 필요한 라이브러리
ImpalaJDBC41.jar commons-logging-X.X.X.jar hadoop-common.jar hive-common-X.XX.X-cdhX.X.X.jar hive-jdbc-X.XX.X-cdhX.X.X.jar hive-metastore-X.XX.X-cdhX.X.X.jar hive-service-X.XX.X-cdhX.X.X.jar httpclient-X.X.X.jar httpcore-X.X.X.jar libfb303-X.X.X.jar libthrift-X.X.X.jar log4j-X.X.XX.jar slf4j-api-X.X.X.jar slf4j-logXjXX-X.X.X.jar
Impala의 JDBC연동을 위한 설정
com.cloudera.impala.jdbc41.Driver
Jdbc:impla://Host:Port[Schema]:Property1=value;property2=value;...
클라우드데라(Cloudera) 에서 Impala 와 연동할 수 있는 JDBC Driver Class를 제공하고 있기 때문에 클라우드데라(Cloudera) Impala 를 이용하면 GlueJdbcDao Class를 이용하여 Impala와 연동이 가능하다.
applicationContext.xml 의 dataSource 설정
<bean id="test-dataSource" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="com.cloudera.impala.jdbc41.Driver"/>
<property name="url" value="jdbc:impala://XXX.XXX.XXX.XXX:XXXX;AuthMech=0"/>
<property name="username" value="XXXXX"/>
<property name="password" value="XXXXXX"/>
</bean>
<bean id="test-dao" class="com.poscoict.glueframework.dao.jdbc.GlueJdbcDao">
<property name="dataSource" ref="test-dataSource"/>
<property name="queryManager" ref="queryManager"/>
</bean>
<bean id="test-tx" class="com.poscoict.glueframework.transaction.GlueDataSourceTransactionManager">
<property name="dataSource" ref="test-dataSource"/>
</bean>
라이브러리 설정
Maven 기반인 경우 pom.xml 에 dependency를 추가한다.
<exclusions>부분은 해당 라이브러리 사용에 따라 변경 될수도 있습니다.
<dependencies>
... 중략 ...
<dependency>
<groupId>com.apache</groupId>
<artifactId>impala</artifactId>
<version>1.0</version>
<scope>system</scope>
<systemPath>C:/eclipse/users/GlueSDK/repo/ext/ImpalaJDBC41.jar</systemPath>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>0.13.1-cdh5.2.1</version>
<exclusions>
<exclusion>
<artifactId>log4j</artifactId>
<groupId>log4j</groupId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.5.0-cdh5.2.1</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
<exclusion>
<artifactId>log4j</artifactId>
<groupId>log4j</groupId>
</exclusion>
</exclusions>
</dependency>
... 중략 ...
</dependencies>
Java 기반 라이브러리
ImpalaJDBC41.jar hive-common-X.XX.X-cdhX.X.X.jar hive-jdbc-X.XX.X-cdhX.X.X.jar hive-metastore-X.XX.X-cdhX.X.X.jar hive-service-X.XX.X-cdhX.X.X.jar httpclient-X.X.X.jar httpcore-X.X.X.jar libfb303-X.X.X.jar libthrift-X.X.X.jar
Search : GlueJdbcDao Class의 find메서드를 이용하여 데이터의 Search가 가능하다.
Named 쿼리와 결과 값으로 VO 객체의 맵핑 모두 가능하다.
GlueGenericDao dao = (GlueGenericDao)GlueStaticContext.getBeanFactory().getBeanObject("test-dao");
// 혹은 GlueGenericDao dao = this.getDao( "test-dao" );
List<Object> list = new ArrayList<Object>();
list.add( 30 );
GlueParameter<List<Object>> listParam = new GlueParameter<List<Object>>();
listParam.setParameter( list );
//일반 쿼리에서 Search, 결과값 Map
List<Map> uslist = dao.find("sample.emp.select",listParam);
//일반 쿼리에서 Search, 결과값 VO객체
List<EmpVO> uslist2 = dao.find("sample.emp.select.vo",listParam);
Map<String,Object> map = new HashMap<String,Object>();
map.put("deptno", 30 );
GlueParameter<Map<String,Object>> mapParam = new GlueParameter<Map<String,Object>>();
mapParam.setParameter( map );
//Named 쿼리에서 Search, 결과값 Map
uslist = dao.find("sample.emp.select.named",mapParam);
// Named 쿼리에서 Search, 결과값 VO객체
uslist2 = dao.find("sample.emp.select.named.vo",mapParam);
Insert : GlueJdbcDao Class의 insert메서드를 이용하여 데이터의 insert가 가능하다.
GlueGenericDao dao = (GlueGenericDao)GlueStaticContext.getBeanFactory().getBeanObject("test-dao");
// 혹은 GlueGenericDao dao = this.getDao( "test-dao" );
List<Object> insertlist = new ArrayList<Object>();
insertlist.add( 3 );
insertlist.add( "test3" );
insertlist.add( 9000 );
insertlist.add( 30 );
GlueParameter<List<Object>> insertParam = new GlueParameter<List<Object>>();
insertParam.setParameter( insertlist );
dao.insert("sample.emp.insert", insertParam);
Impala에서는 Insert의 두가지 구문( into, overwrite)을 지원하는데 두 구분 모두 insert 메소스를 사용 가능 합니다. (아래 예 참고)
insert into val_test_1 values (100, 99.9/10, 'abc', true, now());
insert OVERWRITE emp(empno, ename, sal, deptno) select empno, ename, sal, deptno from emp;
List<Object> list = new ArrayList<Object>();
list.add("30"); //실행 바인딩해야 할 값은 Integer이므로 Integer 변환하여야 에러가 발생하지 않는다.
GlueParameter<List<Object>> listParam = new GlueParameter<List<Object>>();
listParam.setParameter( list );
List<Map> uslist = dao.find("sample.emp.select",listParam);
그 외에도 Impala의 SQL 문법에 대해서는 자세한 내용은 Impala SQL Language을 참고하시기 바랍니다.
